Software Design Using C++Basics of Data StreamsIntroductionOften we want a program to process a long sequence of data. In this Web page we will only consider the processing of a sequence of numbers. These numbers can be read from the keyboard (that is, interactively from the user) or from a text file. We will also consider how to write this type of data to a text file. Other types of data and other types of file handling are discussed in the intermediate section of these Web pages under the heading of Files (Streams). The basic idea when reading number data is that we will read in numbers until we cannot read any more. If we are reading the data from a file, we could say that we are reading data until we reach the end of the file (EOF, for short). In reading data interactively from the keyboard, we instruct a Windows user to press CTRL z to signal the end of the data. (This means to hold down the CTRL key and touch the z.) CTRL z is essentially the EOF signal for interactive input. In Linux this would have to be changed to CTRL d, as that is the correct EOF signal there. In general, input and output operations tend to be a bit system-dependent. That is, when switching from one operating system to another, or one C++ compiler to another, you may find small differences that cause a program that works in one setting not to work in the other. Just be aware of this possibility and be prepared to deal with it if necessary. Reading from the KeyboardLook at the program readkeyb.cpp to see how to read a stream of numbers from the keyboard. This program reads in a stream of floating point numbers and then prints out their average. Part of the code is shown below. The initialization of the variables and the printing of the average have been left out here in order to save space.
The only thing really new here is the use of Remember that the ! symbol is the boolean NOT operation. (See the discussion on Compound Conditions, under the "Decisions, Decisions" topic, for more information on boolean operations.) The overall idea in the above code is that we go through the loop body as long as the preceding input operation did not fail.
There is also an
Notice that
Reading from a Text FileSee the program readfile.cpp for a simple example of how to read numbers from a text file until the end of file has been reached. The program reads floating point numbers and prints the average once end of file has been reached, much like the above example. The main difference is that this program reads the numbers from a text file. A text file is the type of file consisting of lines of characters. (See Files (Streams) for more information on types of files.) A text file can be created by NotePad in Windows, Edit in DOS, etc. There is even an icon for creating a new text file in Visual C++ Developer Studio. In fact, our program files are text files themselves, although their names end with the .cpp extension instead of the usual .txt extension used by most text files on a PC. According to the comments at the top of the program, the numbers in the text file must be placed on separate lines or separated by blank space. That is how the different numbers are distinguished. For an example of such a file click see this version of readfile.txt.
Near the top of the program you will see the inclusion of a new header. The
Below we have pasted in the entire main function, the only function in this
program. Note that it creates a variable called
The
Right after we try to open the file, there is a test of
Why would
The heart of the program is the same as in the previous example, except that
the data is read from
After computing and printing the average, the program ends by closing
the data file. Get into the habit of always closing your data files
as soon as you are done with them. With some languages and compilers
this is not necessary, but with others it is, so it is best to always close
your files. Besides, it consumes some computer resources to keep a file
open, so it is best to close it as soon as possible.
The command for closing
There are other ways to set up files instead of using Writing to a Text FileWriting numbers to a text file is rather similar. The makefile.cpp example shows how to produce the type of text file that was used as input for the above example. One key difference is to use ios::out to open the file in output mode. Then you use the << operator to write each number to the output file stream. Be sure to close the file at the end as failure to do so often means that some data does not really get written out to the file. (This is because output to a file is often "buffered", which means that it is saved up and only flushed out to the file on occasion. The close will force all saved data to be flushed to the file. Here is the essential code for writing to our readfile.txt file:
Passing File Streams as ParametersA file stream can be passed as a parameter to a function, but it must be a reference parameter. The readfile2.cpp example is a reworked version of our readfile.cpp program. However, the new version does most of the file processing in a function. Note that the file stream is opened for input in the main function and is then passed as a reference parameter to the helping function ProcessFile.
Formatted Output to a File StreamIt is also possible to nicely format the numbers that are written to a text file. See the makegradefile.cpp example, the essentials of which are shown below. Note how the setf function is used to set some formatting flags for the output stream. In particular, it is used to say that we want fixed point numbers. (The other option is ios::scientific for scientific notation, which uses an exponent.) The setpoint flag is used to say that we want to see the decimal point and trailing zeros in a number like 3.00, rather than a 3 with no decimal point. We also use the precision function to specify that we want our numbers rounded to 2 decimal places when they are written to the file. Note the use of the setw "manipulator" function in the output command that writes data to the file. This is used to set the width of the field holding the number. In our case, a width of 12 is used. In order to use the setw function you have to include the iomanip header. Also be aware that the setw command only affects the very next item that is output to the file stream. Thus you may need to use setw several times to get the effect that you want. To see its effect on a file, see the following example version of gradefile.txt
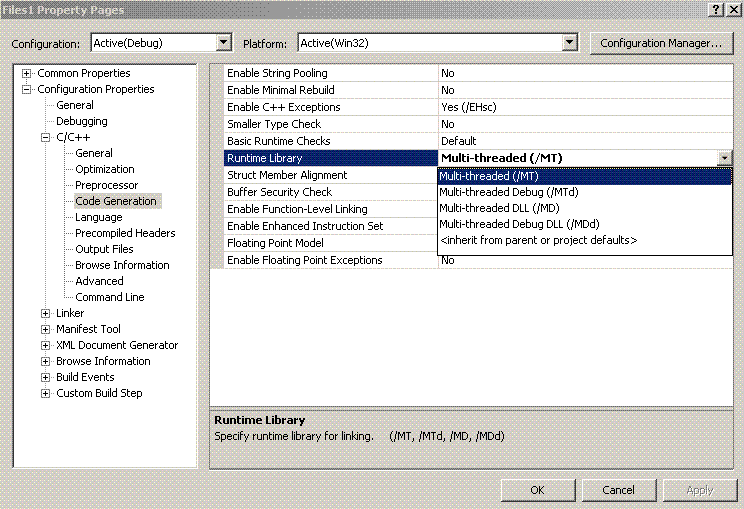
A Dark GDK ExampleLet's now consider the application of files to using Dark GDK. Before doing using our example code, you will need to make the following change to the project set up for the Dark GDK App discussed below. In Visual Studio, go to Project -> Properties and in that configuration window go to Configuration Properties -> C/C++ / Code Generation and set Runtime Library to Multi-threaded (/Mt). As was stated before, this will need to be done in the Dark GDK project below but first, let us quickly review a helper program which has been written for this. We would like to create a Dark GDK Program which reads an input file and draws some circles and rectangles. To write the input files for this by hand could become rather confusing, particularly if we are frequently alternating the type of shape that we want to draw. What we can do to help is write a program which will prompt the user for the configuration of their drawing and use that to create the file. (What this also allows us to see is how two programs can interact through the intermediary of a file. A far more sophisticated example of this would be the Warcraft III Map Editor which allows users to design maps and save them for use in Warcraft III. Of course, we could come up with a whole variety of such examples in the world of Business, Games, Utilities, etc. Our helper application is CreateShapeFile.cpp. There is little new in it from what we have discussed earlier regarding file creation. For reference, you can see fileformat.txt and a simple output file, drawing.txt.
Now we need to consider the program which reads this file and displays it,
ShapeLoader.cpp. On the whole, the main body is rather simple
and revolves around a simple switch statement which branches the code based on the first number on each
line (the "shape type" indicator for either rectangle or circle).
The logic within each case handles the expected data. The error handling is not overly robust, but we must accept that at this point in our lectures. The drawing functions should look familiar, though one has taken a slightly different twist, namely "DrawBall." In a previous example, a ball was drawn very simply, by drawing multiple concentric circles which ultimately give the appearance of a full "ball." Ultimately, this is going to involve quite a bit of processing as each circle is created. On the whole, the operation is relatively simple thanks to the symmetry of the circle about its center. In order to render an entire circle, we could consider several possible algorithms, each of which becomes less and less computationally involved. The following material is optional and provided for your own edification, though it may be a bit intense for a new algorithmist. Therefore, it is optional, though recommended for eventual review. In the examples which follow, we will assume the following definitions: {r => radius; cx => center x coordinate; cy => center y coordinate; these last two apply also for any other point arbirarily named (e.g. p = (px,py), r = (rx,ry), etc.}
As is obvious from these three examples, there are multiple ways to approach this one graphics problem. Each has its own strengths and weaknesses in various categories (readability, execution speed, memory use - though not to much of a degree in this latter). There are still other ways you could solve this problem with other algorithms and graphics primitives. Perhaps you can think of a few and even test them for their relative merits. Related Items
|
Computing & Information Systems |
|

 Search CIS Site
Tutorials
Search CIS Site
Tutorials
|
{kind=link}